What is Robots.txt?
Robots.txt is a text file that webmasters create and implement on their website to inform search engine crawlers (also known as bots) which pages or files on the website the crawler can or cannot crawl.
A robots.txt file is not a way to completely keep a webpage out of the Google index. (If that is your objective, use noindex directives instead.)
The file is a part of the REP, or robots exclusion protocol. These protocols determine how robots on the internet crawl and index content.
Examples of Robots.txt
Example 1
User-agent: *
Allow: /
Sitemap: http://www.example.com/sitemap.xml
In the example above, all user agents can access the site in its entirety.
Example 2
User-agent: *
Disallow: /
In the example above, all user agents cannot access the site.
Other Examples
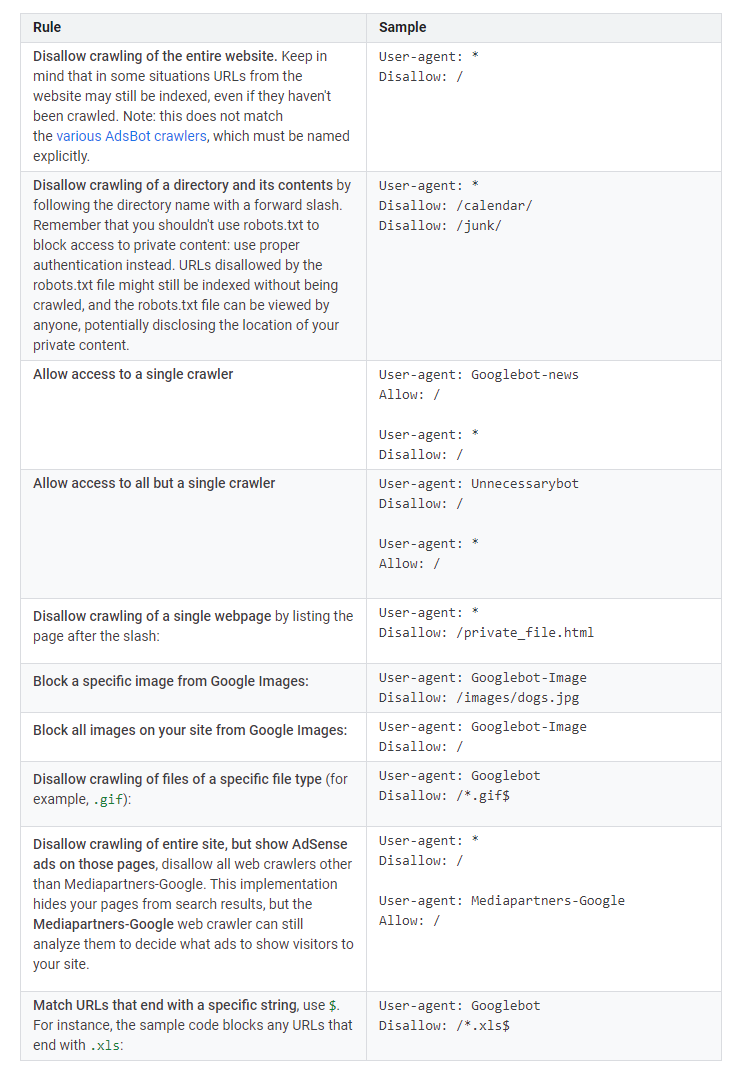
Below you can see various examples of the robots.txt file as explained by Google.
How to View Robots.txt Files
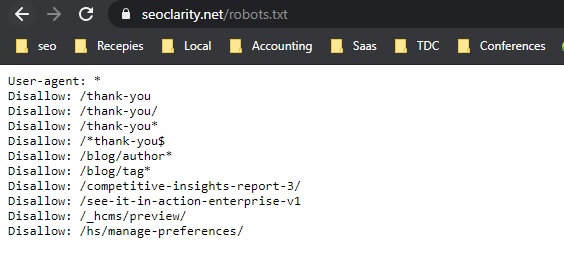
Most robots.txt files can be viewed by going to www.yoursite.com/robots.txt.
Here is how that looks for seoClarity’s domain:
Guidelines for Robots.txt Files
There are various specifications to the robots.txt file that you should be aware of. Knowing this will help you better understand the creation of a robots.txt file.
Format and Location
When creating the file with your text editor of choice (not a word processor), ensure that it is able to create UTF-8 text files.
Then, follow these recommendations so you can properly implement your file:
- File name must be “robots.txt” - this is case sensitive as well
- Only one robots.txt file is allowed per site
- The file must be at the root of the website host
- The file can apply to subdomains and non-standard ports
- Use a hashtag mark (i.e. #) to denote a comment follows
- Include the location of the sitemap at the bottoms of the file
Syntax
Before you get started creating your robots.txt file, there are a few terms you’ll need to be familiar with.
- User-agent: The specific web crawler to which you’re giving crawl instructions (usually a search engine).
- Disallow: The command used to tell a user-agent not to crawl a particular URL. Only one "Disallow:" line is allowed for each URL.
- Allow: This rule (only applicable to Googlebot) tells Google’s crawler that i can access a page or subfolder even though its parent page or parent subfolder may be disallowed.
- Sitemap: This is used to call out the location of any XML sitemap(s) associated with the URL. The search engines that support this command are Google, Ask, Bing, and Yahoo!.
Common Errors With the Robots.txt File
Although they’re extremely helpful files, there are some common elements that can go awry.
We’ve compiled a list of common robots.txt issues to help you better understand the nuances of the file and prevent any avoidable mistakes.