
Robots.txt files are a useful asset in limiting a search engine crawler (like Googlebot) from seeing unimportant pages on your site.
At seoClarity, we recommend Google’s guidelines and best practices: configuring your site to control how non-HTML content is shown in search engine results (or to make sure it is not shown) globally with X-Robots-Tag HTTP headers.
By blocking files via HTTP headers, you ensure that your site doesn't start to see increased indexation of URLs you don't want to appear in search results.
This helps to avoid potential security issues and any potential conflicts that can result from pages being indexed that don't need to be. However, robots.txt can also be an effective means.
Here's what we'll cover in this post:
- What is a Robots.txt file? >
- Why are Robots.txt files important? >
- Common issues with robots.txt >
- Google’s best practices for using robots.txt files >
- How to handle “noindex” attributes >
What is a Robots.txt File?
Robots.txt files inform search engine crawlers which pages or files the crawler can or can’t request from your site. They also block user agents like bots, spiders, and other crawlers from accessing your site’s pages.
A search engine bot like Googlebot will read the robots.txt file prior to crawling your site to learn what pages it should deal with.
This can be helpful if you want to keep a portion of your site out of a search engine index or if you want certain content to be indexed in Google but not Bing, for example.
Below is an example of what a robots.txt file looks like.
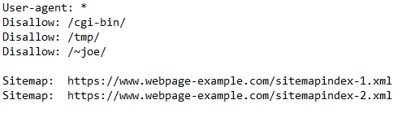 (A robots.txt with the specified user agent, disallow, and sitemap criteria.)
(A robots.txt with the specified user agent, disallow, and sitemap criteria.)
When user agents like bots, spiders, and other crawlers hit your site, they can utilize extensive resources (memory and CPU) and can lead to high load on the server that slows down your site.
Example of a Robots.txt File
Below is an example from Google in which Googlebot has blocked access to certain directories while allowing access to /directory2/subdirectory1/. You'll also see that “anothercrawler” is blocked from the entire site.
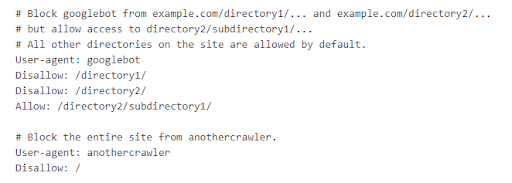
User-agents are listed in “groups." Each group can be designated within its own lines by crawler type indicating which files it can and cannot access.
Collecting bot activity data is especially important for identifying any additional bots, spiders, or crawlers that should be blocked from accessing your site’s content.
Why are Robots.txt Files Important?
Telling a crawler which pages to crawl and which pages to skip lets you have greater control over your site’s crawl budget by directing the crawlers to your most important assets.
By having a robots.txt file in place, you avoid the possibility of overloading your site’s servers with requests.
This is largely because you are able to manage the increase of traffic by crawlers and avoid crawling unimportant or similar pages on your site.
For example, in the sample robots.txt file above there are coding assets stored in the /cgi-bin folder on the website, so adding a disallow line allows for crawlers to note there are no assets within this folder the site would want indexed.
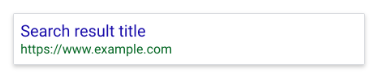 One caveat is that, according to Google, pages that are blocked via robots.txt file may still appear in search results, but the search result will not have a description and look something like this image here.
One caveat is that, according to Google, pages that are blocked via robots.txt file may still appear in search results, but the search result will not have a description and look something like this image here.
If you see this search result for your page and want to fix it, remove the line within the robots.txt entry blocking the page.
Pages that still have backlinks pointing to the page from other places on the web may potentially still appear in search results.
To properly prevent your URL from appearing in Google Search results, you should password protect the files on your server or use the noindex meta tag or response header (or remove the page entirely via 410 or other means).
You can also designate within the robots.txt file which assets you want to prevent from appearing in search results including specific images, video, and audio files, as well as block unimportant image, script, or style files (if you think that pages loaded without these resources will not be significantly affected by the loss).
Recommended Reading: Technical SEO: Best Practices to Prioritize Your SEO Tasks
Because robots.txt files indicate to crawlers which pages and resources not to crawl (and therefore those that won't be indexed) they should be reviewed to ensure the implementation is correct.
If pages are disallowed from crawling through the robots.txt file, then any information about indexing or serving directives will not be found and will therefore be ignored.
Important resources needed to render page content (including assets needed to load to increase page speed, for example) are needed to be crawled.
If indexing or serving directives must be followed, the URLs containing those directives cannot be disallowed from crawling.
14 Common Issues with Robots.txt
The best way to find robots.txt errors is with a site audit. This lets you uncover technical SEO issues at scale so you can resolve them.
Here are common issues with robots.txt specifically:
#1. Missing Robots.txt
A website without a robots.txt file, robots meta tags, or X-Robots-Tag HTTP headers will generally be crawled and indexed normally.
How this can become an issue:
Having a robots.txt file is a recommended best practice for sites to add a level of control to the content and files that Google can crawl and index. Not having one simply means that Google will crawl and index all content.
#2. Adding Disallow Lines to Block Private Content
Adding a disallow line in your robots.txt file will also present a security risk as it identifies where your internal and private content is stored.
How this can become an issue:
Use server-side authentication to block access to private content. This is especially important for personal identifiable information (PII).
#3. Adding Disallow to Avoid Duplicate Content/Used As Opposed to Canonicals
Sites need to be crawled in order to see the canonical and approximately index. Do not block content via a robots.txt file in an attempt to handle as canonicals.
How this can become an issue:
Certain CMS and Dev environments may make it difficult to add custom canonicals. In this instance, Dev may try other methods as workarounds.
#4. Adding Disallow to Code That is Hosted on a Third-Party Site
If you want to remove content from a third-party site, you need to contact the webmaster to have them remove the content.
How this can become an issue:
This can occur in error when it's difficult to interpret the source server for specific content.
#5. Use of Absolute URLs
The directives in the robots.txt file (with the exception of “Sitemap:”) are only valid for relative paths.
How this can become an issue:
Sites with multiple sub-directories may want to use absolute URLs, but only relative URLs are passed.
#6. Robots.txt Not Placed in Root Folder
The file must be placed in the top-most directory of the website – not a sub-directory.
How this can become an issue:
Ensure that you are not placing the robots.txt in any other folder or sub-directories.
#7. Serving Different Robots.txt Files (Internationally or Otherwise)
It is not recommended to serve different robots.txt files based on the user-agent or other attributes.
How this can become a problem:
Sites should always implement the same robots.txt for international sites.
#8. Added Directive to Block All Site Content
Site owners often in development sprints accidentally trigger the default robots.txt file which can then list a disallow line that blocks all site content.
How this can become a problem:
This usually occurs as an error or when a default is applied across the site that impacts the robots.txt file and resets it to default.
#9. Adding ALLOW vs. DISALLOW
Sites do not need to include an “allow” directive. The “allow” directive is used to override “disallow” directives in the same robots.txt file.
How this can become an issue:
In instances which the “disallow” is very similar, adding an “allow” can assist in adding multiple attributes to help distinguish them.
#10. Wrong File Type Extension
Google Search Console Help area has a post that covers how to create robots.txt files. After you’ve created the file, you can validate it using the robots.txt tester.
How this can become an issue:
The file must end in .txt and be created in UTF-8 format.
#11. Adding Disallow to a Top-Level Folder Where Pages That You Do Want Indexed Also Appear
Blocking Google from crawling a page is likely to remove the page from Google’s index.
How this can become an issue:
This usually occurs due to the placement of the asterix (*). When added before a folder it can mean anything in-between. When it’s added after, that’s a sign to block anything included in the URL after the /.
#12. Blocking Entire Site Access During Development
You can temporarily suspend all crawling by returning an HTTP result code of 503 for all URLs, including the robots.txt file. The robots.txt file will be retried periodically until it can be accessed again.
(We do not recommend changing your robots.txt file to disallow crawling.)
How this can become an issue:
When relocating a site or making massive updates, the robots.txt could be empty default to blocking the entire site. Best practice here is to ensure that it remains on site and is not taken down during maintenance.
#13. Using Capitalized Directives vs. Non-Capitalized
Keep in mind that directives in the robots.txt file are case-sensitive.
How this can become an issue:
Some CMS/Dev environments may automatically set URLs to render the robots.txt in uppercase and lowercase. The directives MUST match the actual 200-live status URL structure.
#14. Using Server Status Codes (e.g. 403) to Block Access
In order to block crawling of the website, the robots.txt must be returned normally (i.e. with a 200 “OK” HTTP result code) with an appropriate “disallow” in it.
How this can become an issue:
When relocating a site or making massive updates, the robots.txt could be empty or removed. Best practice is to ensure that it remains on site and is not taken down during maintenance.
How to Check if Your Site Has X-Robots-Tag Implemented
A quick and easy way to check the server headers is to use a web-based server header checker, or use the “Fetch as Googlebot” feature in Search Console.
Google’s Best Practices for Using Robots.txt Files
#1. Block Specific Web Pages
Robots.txt can be used to block web crawlers from accessing specific web pages on your site, but be sure to follow the seoClarity recommendation below.
seoClarity Tip
If there are specific pages you want to block from crawling or indexing, we recommend adding a “no index” directive on the page level.
We recommend adding this directive globally with X-Robots-Tag HTTP headers as the ideal solution, and if you need specific pages then add the “noindex” on the page level. Google offers a variety of methods on how to do this.
#2. Media Files
Use robots.txt to manage crawl traffic, and also prevent image, video, and audio files from appearing in the SERP. Do note, this won’t prevent other pages or users from linking to your image, video, or audio file.
If other pages or sites link to this content, it may still appear in search results.
seoClarity Tip
If the end goal is to have those media types not appear in the SERP, then you can add it via the robots.txt file.
#3. Resource Files
You can use robots.txt to block resource files, such as unimportant image, script, or style files if you think that pages loaded without these resources will not be significantly affected by the loss.
However, if the absence of these resources make the page harder for Googlebot to understand the page, you should not block them, or else Google will not be able to analyze the pages that depend on those resources.
seoClarity Tip
We recommend this method if no other method works best. If you are blocking important resources (e.g. CSS script that renders the text on the page) this could cause Google to not render that text as content.
Similarly, if third-party resources are needed to render the page and are blocked, this could prove to be problematic.
How to Handle “Noindex” Attributes
Google does not recommend adding lines to your robots.txt file with the “noindex” directive. This line will be ignored within the robots.txt file.
If you still have the “noindex” directive within your robots.txt files, we recommend one of the following solutions:
#1. Use the Robots Meta Tag: <meta name=“robots” content=”noindex” />
The above example instructs search engines not to show the page in search results. The value of the name attribute (robots) specifies that the directive applies to all crawlers.
To address a specific crawler, replace the “robots” value of the name attribute with the name of the crawler that you are addressing.
seoClarity Tip
This is recommended for specific pages. The meta tag must appear in the <head> section. If there are specific pages that you want to block from crawling or indexing, we recommend adding a “no index” directive on the page. Google offers specific methods to do this.
#2. Contact your Dev team responsible for your server and configure the X-Robots-Tag HTTP Header
The X-Robots-Tag can be used as an element of the HTTP header response for a given URL. Any directive that can be used in a robots meta tag can also be specified as an X-Robots-Tag.
Here is an example of an HTTP response with a X-Robots-Tag instructing crawlers not to index a page:
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
(...)
X-Robots-Tag: noindex
(...)
In addition, there may be instances in which you need to use multiple directives. In these instances, directives may be combined in a comma-separated list.
seoClarity Tip
We recommend this as the preferred method for any content you want blocked from search engines. Global Directives on the folder level are needed.
The benefit of using an X-Robots-Tag with HTTP responses is that you can specify crawling directives that are applied globally across a site. This is handled on your server, and in order to implement it you need to discuss with your Dev Team responsible for handling your site’s internal servers.
Key Takeaways
You should review our optimal implementation steps to ensure that your site follows all best practices for robots.txt files and compare your site with the common errors that we’ve listed above.
Then, create a process to handle and remove noindex lines from robots.txt. Conduct a full site crawl to identify any additional pages that should be added as disallow lines.
Make sure your site is not using automatic redirection or varying the robots.txt. Benchmark your site’s performance prior to and after changes.
Do note that our Client Success Managers can assist you in creating those reports to benchmark.
If you need additional assistance, our Professional Services team is available to help diagnose any errors, provide you with an implementation checklist and further recommendations, or assist with QA testing.



1 Comment
Click here to read/write comments